
Stable Diffusion web UIがSDXLに対応したので環境を整えました。
今回もWSLとUbuntuの環境を使って画像生成で遊びたいと思います。
動作にはStable Diffusion web UIが必要になります。
以下にインストール手順をまとめてるので参考にしてください。
[]バージョン1.6でSDXLのrefiner機能が正式にサポートされました。
これまでは手動でモデルを切り替える必要がありましたが、最新版では自動で処理されます。
この機能に関しては後半で解説しますので、web UIのアップデートを行ってください。
ちなみに自身のバージョンが不明な場合、トップ画面の一番下を見ると書いてあります。

[]Stable Diffusion web UIの更新方法について記事を分離しました。
特定バージョンへの更新方法も記載してるので、環境が古い人は参考にしてください。
Stable Diffusion web UIをアップデートする方法です。何となく、ちゃんとまとめました。無理に最新版にする必要もないのですが、新機能が増えたりするので好みで更新してください。[20240821]更新でErrorが発生した場合の対処方法を追加しました。◆ Stable Diffusion web UIのインストール方法について◆ 学習モデルのダウンロード方法と追加方法について◆ CUDA ToolkitやcuDNNを更新する方法について...
◆ Stable Diffusion web UIのインストール方法について
純正のStable Diffusionをコマンド実行するのは実用的に厳しいです。なので、最も人気のあるStable Diffusion web UIをWSLとUbuntuの環境に構築したいと思います。[20240303]環境構築後にCUDA ToolkitやcuDNNを更新する方法です。本記事のバージョンが合わない場合、以下の記事も参考にしてください。[20240620]Stable Diffusion web UIを更新する方法です。既に環境を構築済みの人は参考にしてください。...
◆ 学習モデルのダウンロード方法と追加方法について
モデル増えるの早すぎて進化に追いつけません! という事で今回はモデルを探す手順やダウンロードする方法を解説します。◆ Stable Diffusion web UIのインストール方法について学習モデルを探す方法僕の場合はGoogle検索するかHuggingFaceを適当に散策するかです(雑)。それを探す方法とは言わない...今回の説明ではCounterfeitを例にします。以下がHuggingFaceのリンクです。https://hugging...
Stable Diffusion web UIをアップデート
SDXLを利用するためには、Stable Diffusion web UIのバージョンが1.5以上である必要があります。
また、refiner機能がサポートされたのが1.6のため、実質的に1.6以上でないと動きません。
Stable Diffusion web UIをアップデートする方法です。何となく、ちゃんとまとめました。無理に最新版にする必要もないのですが、新機能が増えたりするので好みで更新してください。[20240821]更新でErrorが発生した場合の対処方法を追加しました。◆ Stable Diffusion web UIのインストール方法について◆ 学習モデルのダウンロード方法と追加方法について◆ CUDA ToolkitやcuDNNを更新する方法について...
学習モデルとVAEの追加
SDXLにはBaseとRefinerの2種類のモデルがあります。Baseが通常利用するモデルでRefinerがimg2imgで利用するモデルです。
これはBaseで生成した画像を元にRefinerで再生成を行うことで、画質を向上させることができます。
各モデルとVAEは以下にあります。
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0
https://huggingface.co/stabilityai/sdxl-vae
では、これらを次のコマンドで追加しましょう。
cd ~/stable-diffusion-webui
wget https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors -O ./models/Stable-diffusion/sd_xl_base_1.0.safetensors
wget https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors -O ./models/Stable-diffusion/sd_xl_refiner_1.0.safetensors
wget https://huggingface.co/stabilityai/sdxl-vae/resolve/main/sdxl_vae.safetensors -O ./models/VAE/sdxl_vae.safetensors
WSLのメモリ不足対策
ダウンロードした時点でお気づきかもしれませんが、モデルのファイルサイズが非常に大きいです。
そのため、WSL経由で利用するとモデルを変更する時にメモリ不足でプロセスが落ちます。
これの解決は物理メモリの強化ですが、それはお金も掛かるし、そもそも僕の環境32GBなんですよね。

32GBって一般的に多い方では?

まさかミジンコPCだったか。もっと精進します。
では、どうするかですが、仕方がないので仮想環境のメリットを活かしてSSDを多少犠牲にします。
Swap(スワップ)と呼ばれる機能があり、これを使うとSSDの一部をメモリとして利用できます。
Windowsのユーザー用フォルダに次のファイルがあるので、好きなテキストエディタで開いてください。
C:\Users\(ユーザー名)\.wslconfig
このファイルの中身に以下を記述します。値は好きに変更しても大丈夫です。
[wsl2]
memory=16GB
swap=64GB
有効化はWSLの再起動が必要です。次のコマンドをWindows側で実行しましょう。
wsl.exe --shutdown
動作確認
これで追加作業は終わりです。さすがweb UIです。WSL以外の部分は簡単でしたね。
では、いつも通りの手順で起動してブラウザからアクセスしましょう。
./webui.sh
Baseモデルの利用
今までと利用方法は変わりません。ただし、SDXLは推奨サイズが1024x1024となり、これ以外を選択すると効果が薄れます。
Base用のモデルとVAEを選択して好きなプロンプトを入力。いつも通りGenerateで生成できます。
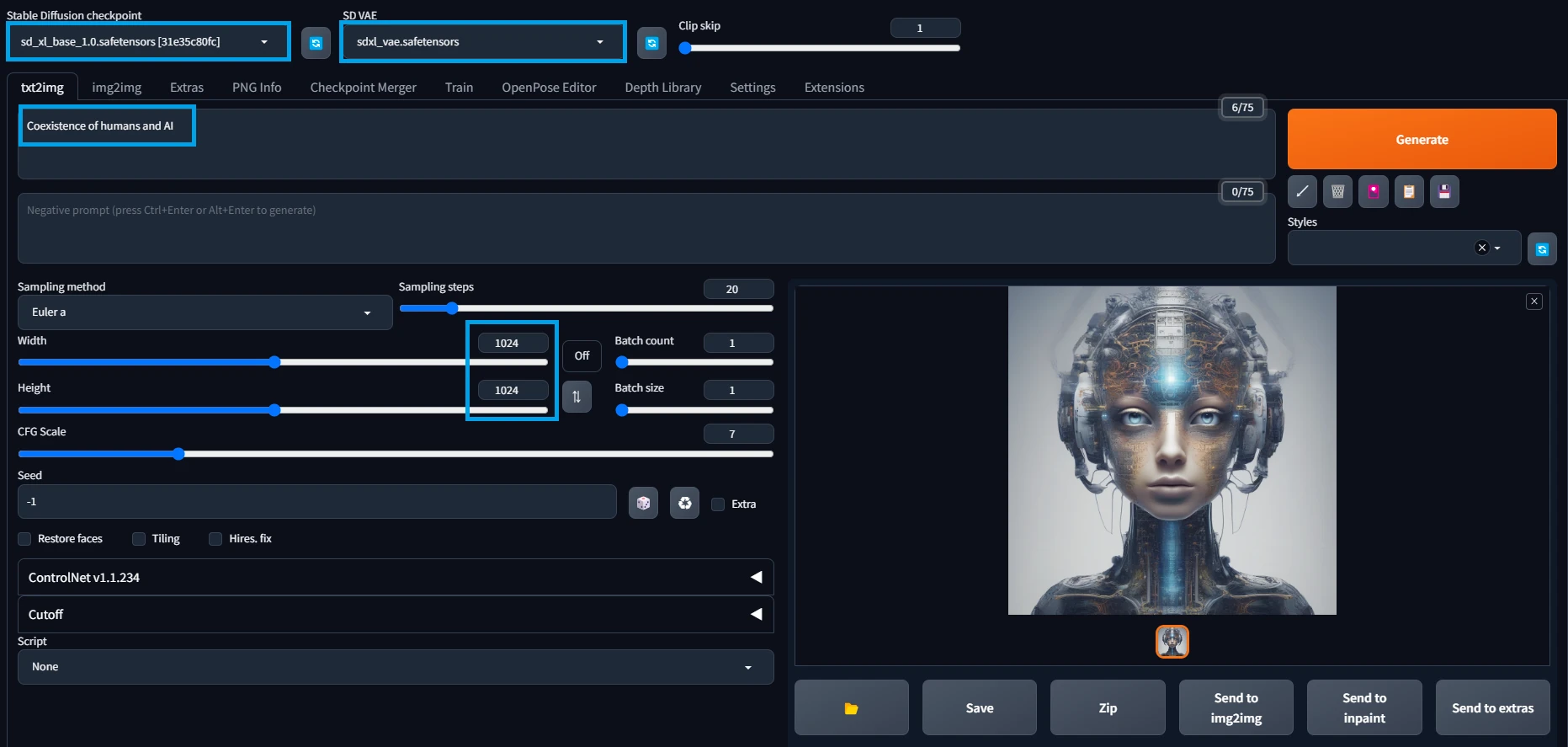

ParametersSampler: Euler a, Steps: 20, CFG scale: 7, Seed: 1986473260, Size: 1024x1024, Model: sd_xl_base_1.0
PromptCoexistence of humans and AI
NegativePrompt未使用
プロンプトの意味は人間とAIの共存。いや、共存どころか融合してるが...
なるほど。人間がAIに取り込まれることが共存なんですね。
せめて逆では。
Refinerモデルの利用 (Version 1.5以前)
先に伝えた通り最新版は自動でモデルが切り替わります。そのため、本手順は無視して構いません。
現時点ではRefinerはちょっと使い勝手が悪いです。単にtxt2imgで生成した画像をimg2imgするだけですが、この時にモデルを変更する必要があります。
そのため、軽い気持ちで生成と再生成を繰り返すのは無理があります。ここは未来のアップデートに期待しましょう。
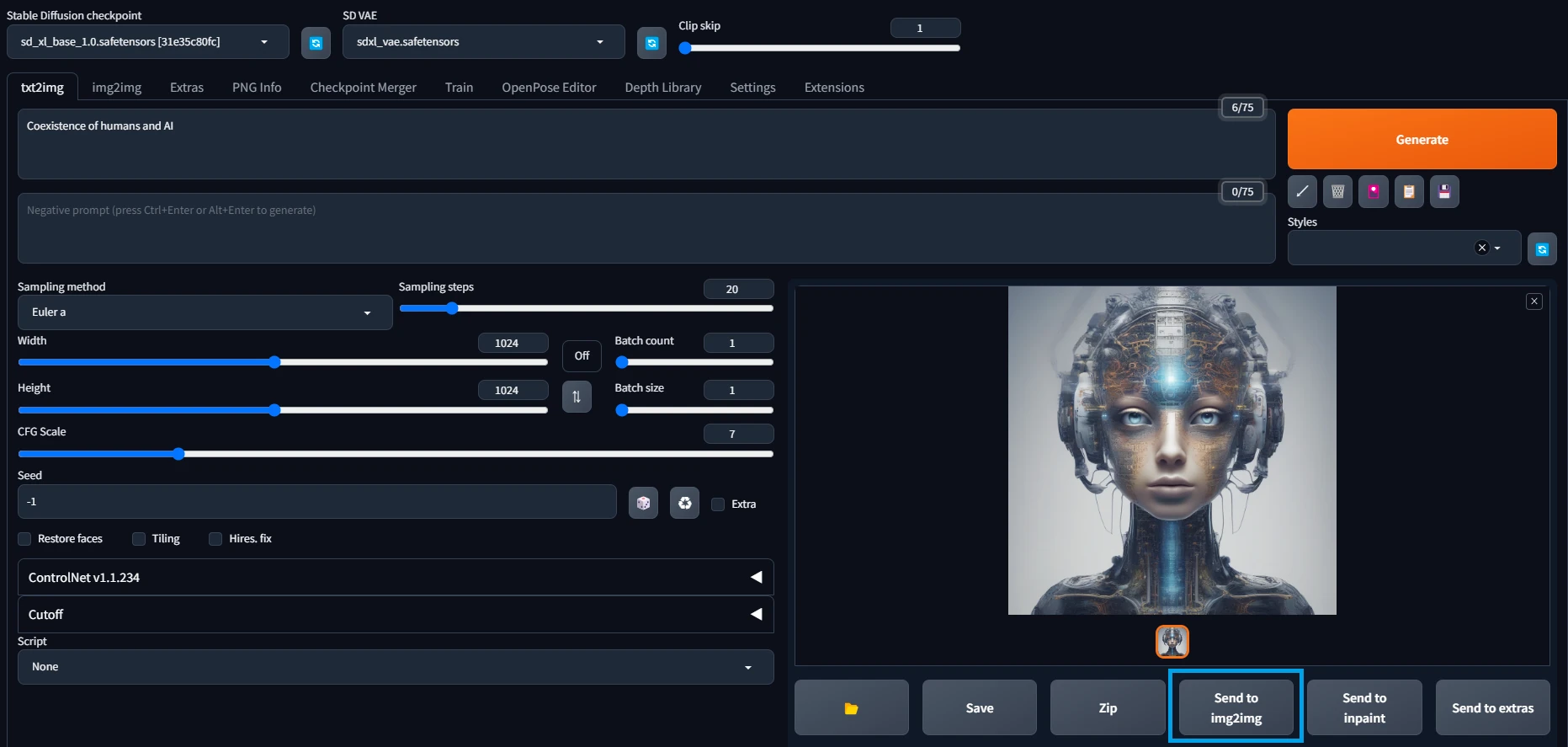
使い方はtxt2imgで画像を生成した後、下の方にあるSend to img2imgを選択します。
そうすると利用したプロンプト等の情報を簡単に引き継げます。モデルは手動で変更してください。
ただし、このまま生成すると全然違う画像になってしまうので、Denoising strengthの値を0.1くらいまで下げます。

そして再生成した画像がこちらです。追加の描き込みにより繊細差が増しました(たぶん)。

ParametersSampler: Euler a, Steps: 20, CFG scale: 7, Seed: 1959981540, Size: 1024x1024, Model: sd_xl_refiner_1.0, Denoising strength: 0.1
PromptCoexistence of humans and AI
NegativePrompt未使用
Refinerモデルの利用 (Version 1.6以上)
まずは通常通りRefiner以外の設定を行います。Baseとなるモデルに対して、いつもと同じ様に設定をしましょう。
そして通常の設定が終わったらRefinerに関する設定を行います。まずは次の画像を見てください。
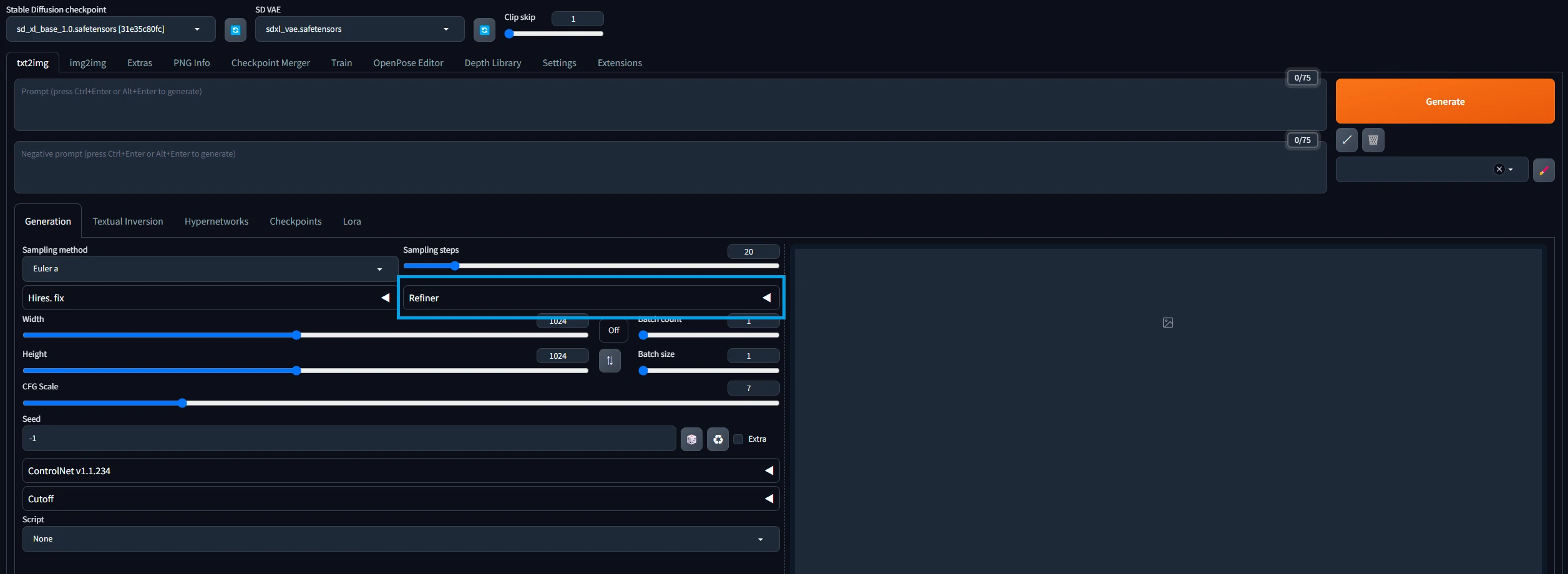
この青枠部分がRefinerに関する設定になります。ここをクリックすると設定可能な項目が展開されます。
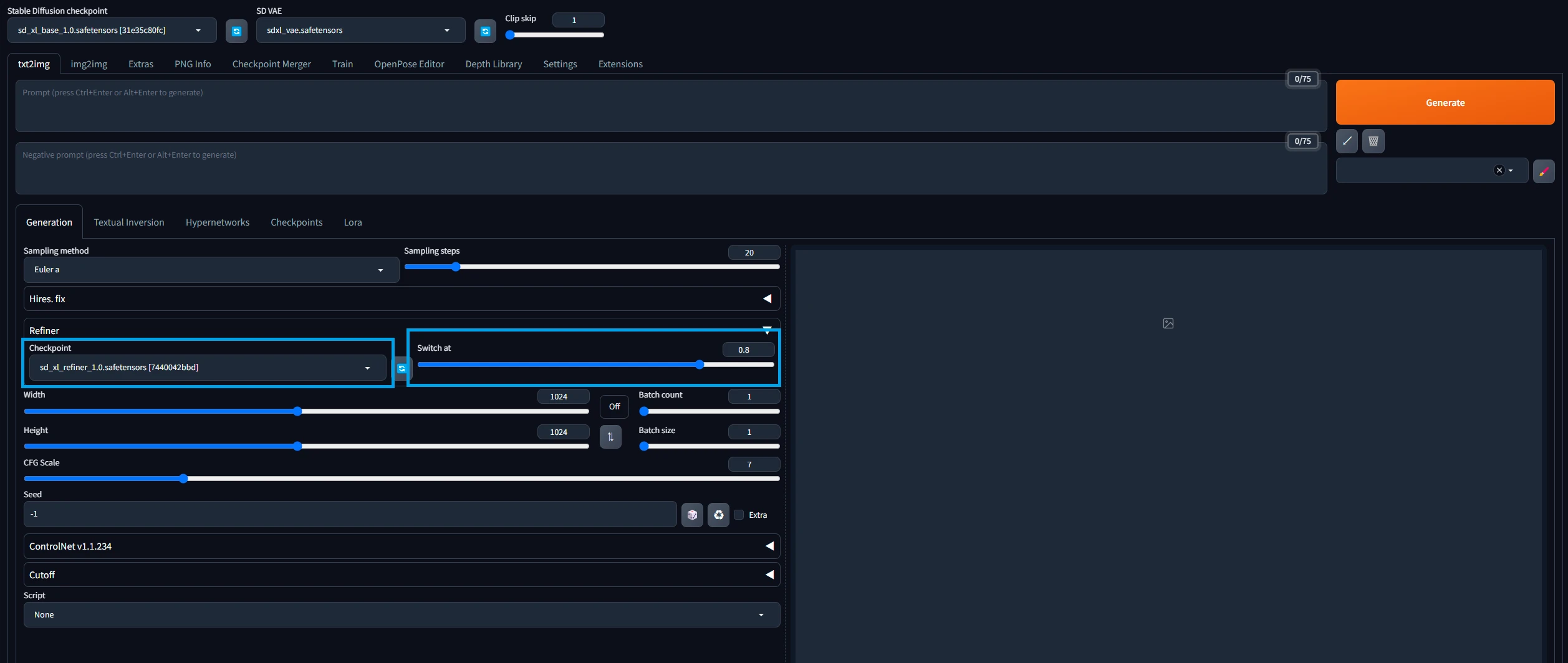
設定項目は2つです。1つ目はRefinerで利用するモデルです。SDXL用のRefinerモデルを選択してください。
2つ目は、どのタイミングでモデルを切り替えるかです。これはSwitch atの数値で設定します。
仕組みは簡単でSampling stepsにSwitch atを掛けた数値を超えるとモデルが自動的に切り替わります。
例としてSampling stepsが20でSwitch atが0.8なら、20 x 0.8 = 16となり、16ステップを超えると利用するモデルが変わります。
設定はこれだけです。手動で切り替えるのと比べて凄く楽ですよね。
では、いつも通りにGenerateで画像を生成しましょう。

ParametersSampler: Euler a, Steps: 20, CFG scale: 7, Seed: 2255638359, Size: 1024x1024, Model: sd_xl_base_1.0, VAE: sdxl_vae.safetensors, Refiner: sd_xl_refiner_1.0, Refiner switch at: 0.8
PromptThe coolest future robot
NegativePrompt未使用
意味は「最高にかっこいい未来のロボット」です。いや、これラピュタでは...
むしろ古代のロボット感ある。
あとがき
描画される絵が繊細すぎて震えました。また、1.6以上ならRefinerの利用も現実的になり、手動と比べて格段に使い勝手が向上してます。
ただし、SDXLはモデルの大きさやRefinerの存在により生成に要する時間が増加しました。前みたいに適当に連打できないのが辛いですね。
今後は続々とアニメ系のモデルも登場するでしょうし、みなさんも今のうちにSDXLに対応しては如何ですか?
この記事は参考になりましたか?
コメント