
今回はStable Diffusion web UIでAnimateDiffを利用する方法の紹介です。
そう巷で噂のAIでアニメーション出来ちゃうってやつです。凄いですよね。

流れに乗るの遅くない?

AI関連の調査は丸っと1日くらい使いたいんだけど、いつも気がついたら夜なんだな。
◆ Stable Diffusion web UIのインストール方法について
純正のStable Diffusionをコマンド実行するのは実用的に厳しいです。なので、最も人気のあるStable Diffusion web UIをWSLとUbuntuの環境に構築したいと思います。[20240303]環境構築後にCUDA ToolkitやcuDNNを更新する方法です。本記事のバージョンが合わない場合、以下の記事も参考にしてください。[20240620]Stable Diffusion web UIを更新する方法です。既に環境を構築済みの人は参考にしてください。...
必要機能の追加
前提条件としてAnimateDiffは以下の条件を満たさないと使えません。
- Stable Diffusion web UIがバージョン1.6以上
- ControlNet(拡張機能)がバージョン1.1.410以上
Stable Diffusion web UIに関しては、この辺を参考に更新してください。
Stable Diffusion web UIがSDXLに対応したので環境を整えました。今回もWSLとUbuntuの環境を使って画像生成で遊びたいと思います。動作にはStable Diffusion web UIが必要になります。以下にインストール手順をまとめてるので参考にしてください。[20230909]バージョン1.6でSDXLのrefiner機能が正式にサポートされました。これまでは手動でモデルを切り替える必要がありましたが、最新版では自動で処理されます。この機能に関しては...
ControlNetに関しては導入が過去すぎて覚えてないのですが、拡張機能に存在していた気がします。
この後の手順でAnimateDiffを追加する時に一緒に導入するか、僕の過去記事を参考にしてください。
Stable Diffusion web UIがポーズを指定できるようになったと聞いて、自分の環境にも適用しました。[20231108] ControlNet 1.1について気がついたら色々と変わってました。特にControlNet 1.1(現行版)は利用するモデルが変わったみたい。関連部分を全部を書き直すと辛いので、ダウンロード対象のモデルだけコマンド類を書き直しました。利用方法も拡張されてますが、既に利用してるユーザーなら感で操作できると思います(丸投げ)。◆ Stable Diff...
AnimateDiffの追加
本題のAnimateDiffですが、拡張機能として提供されるためUI操作で簡単に追加できます。
まずはUIの[Extensions -> Available]に移動、そこに表示される[Load from:]ボタンを押します。

そうするとインストール可能な拡張機能が色々と出現するので、この中から[sd-webui-animatediff]を探してインストールします。

インストールが完了したらweb UIを再起動しましょう。
モデルの追加
拡張機能を利用するためにはモデルが必要になります。公式説明にモデルのリンクが複数あるので好きなモデルを入手します。
そして入手したモデルをextensions/sd-webui-animatediff/modelのディレクトリに配置します。
https://github.com/continue-revolution/sd-webui-animatediff#model-zoo
僕は拡張子がsafetensorsの形式が欲しかったので、以下を入手しました。
モデルの種類で結果も変わるようですが、同じモデルなら次のコマンドで入手できます。
cd ~/stable-diffusion-webui
wget https://huggingface.co/guoyww/animatediff/resolve/refs%2Fpr%2F3/mm_sd_v15_v2.safetensors -O ./extensions/sd-webui-animatediff/model/mm_sd_v15_v2.safetensors
過去バージョンが必要な場合はこちらも使ってください。
cd ~/stable-diffusion-webui
wget https://huggingface.co/guoyww/animatediff/resolve/refs%2Fpr%2F3/mm_sd_v15.safetensors -O ./extensions/sd-webui-animatediff/model/mm_sd_v15.safetensors
wget https://huggingface.co/guoyww/animatediff/resolve/refs%2Fpr%2F3/mm_sd_v14.safetensors -O ./extensions/sd-webui-animatediff/model/mm_sd_v14.safetensors
以下は調べたモデルの特徴です。容量に余裕があるなら全て追加しましょう。
| mm_sd_v14 | モーションの動きが大きいが破綻しやすい。 |
| mm_sd_v15 | モーションの動きは小さいが安定してる。 |
| mm_sd_v15_v2 | そこそこ動いて安定してる。 |
プロンプトに関する設定値の変更
最初は設定値を変えずに数時間くらい試したんですが、どれも良い結果にならなくて精神崩壊しそうな画像を永遠みせられました。
具体的にはこんな感じで、顔面が崩壊するか背景が禍々しい画像が出力されます。たぶん、利用するモデルに依存します。

目が...
みんなの心の平穏のため結構まともなのを選びました。
では、必要な設定ですが、これはドキュメントを真面目に読むと書いてあります。
設定が必要な理由を翻訳すると「無関係な2つのGIFが生成されるのを防ぐため」らしいです。
Pad prompt/negative prompt to be same length
この設定が解決に繋がったかは分かりませんが、比較的まともな画像が出力されるようになりました。
設定は[Settings -> Optimizations]の中にあります。以下の画像を参考に有効化してください。
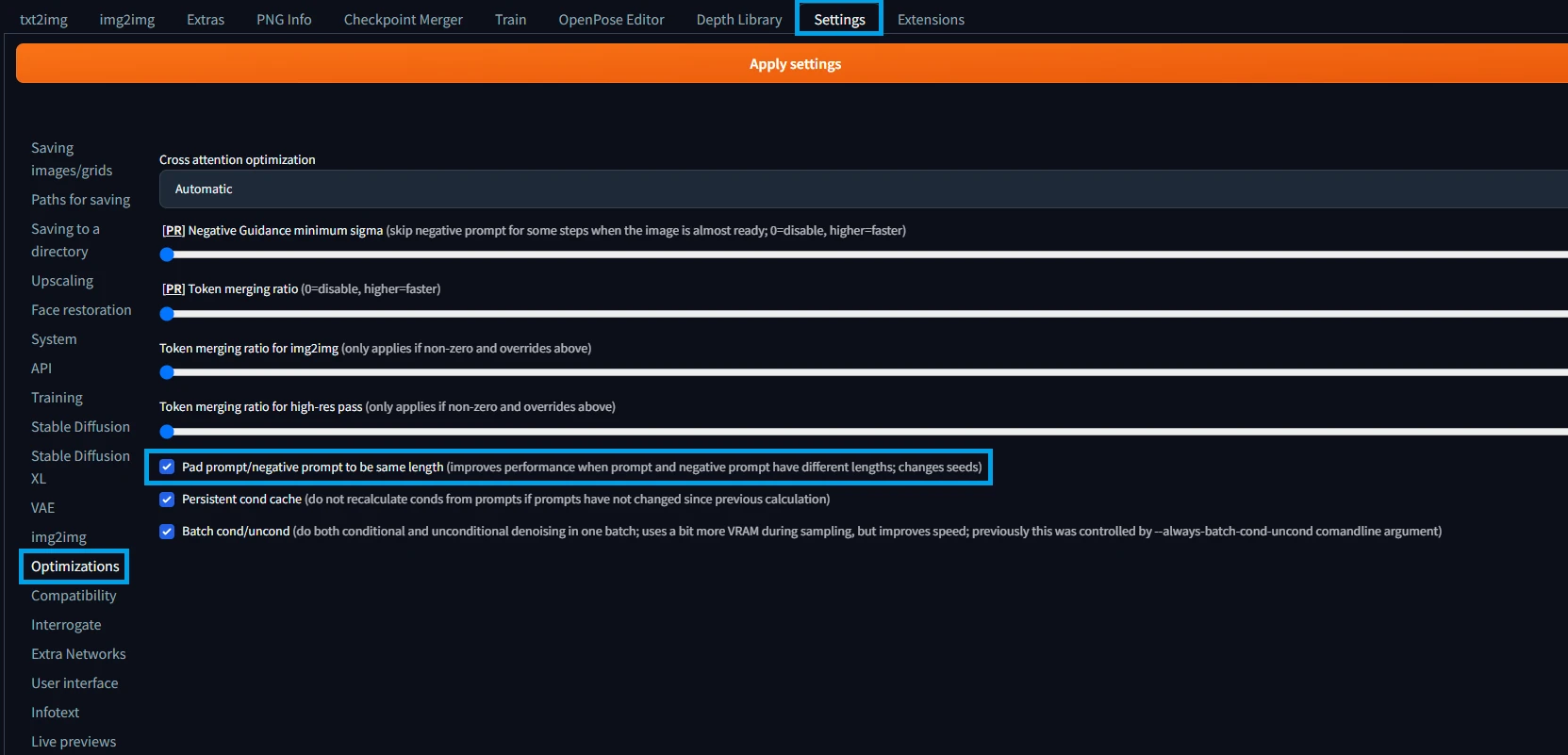
ドキュメントにも書いてある通り、弊害として実行時のVRAM使用量が増えます。
ぱっとみ8GB~10GBくらい使ってました。ちなみにAnimateDiff自体は12GB以上を推奨してます。
アニメーション画像の生成
ここからは実際にアニメーション画像を生成しましょう。
基本的にはUIにAnimateDiffに関する設定が増えてるので、そこをポチポチするだけです。
まずは増えてる項目を確認しましょう。以下の画像を参考にUIを操作してください。
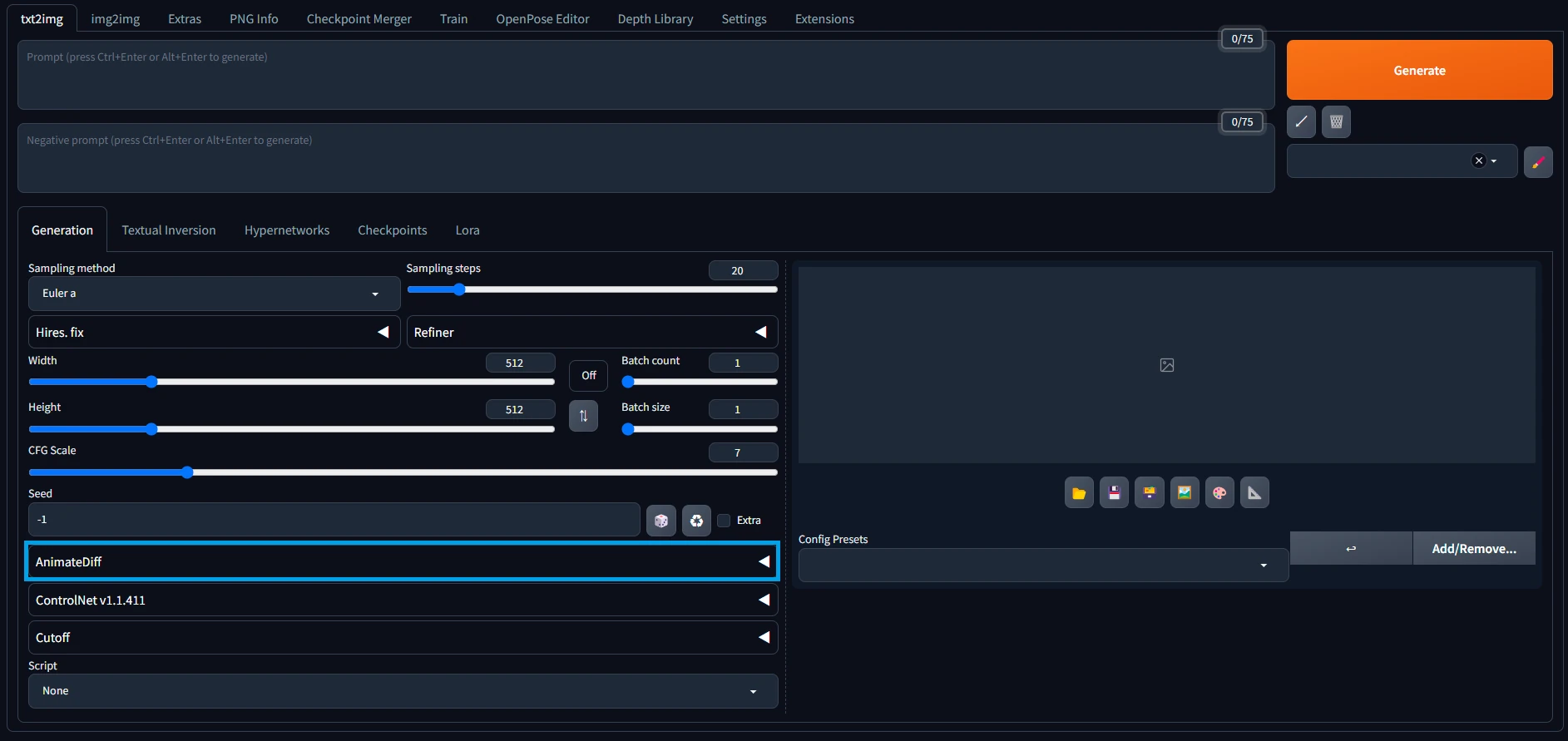
項目を展開するとこんな感じです。
この設定はtxt2imgとimg2imgの両方にあり、テキストか画像のどちらをベースにするかで使い分けます。
どちらを使うかを決めたらAnimateDiffに関する項目を設定します。と言っても、殆どデフォルトで大丈夫です。
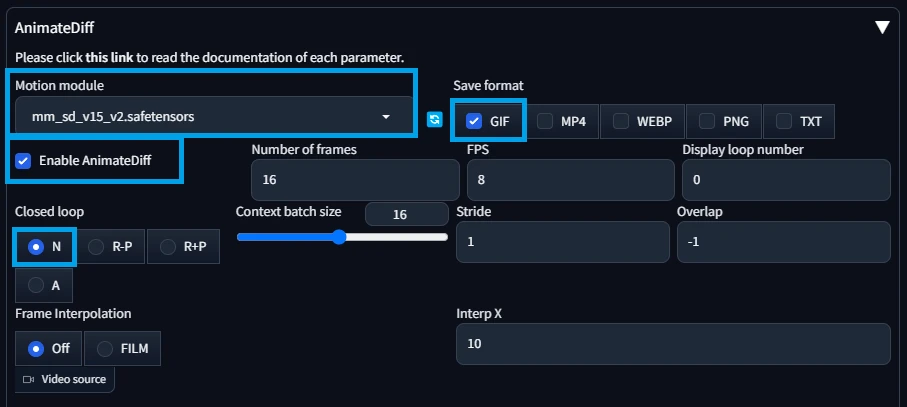
設定が必須なのは利用モデルと有効化(Enable AnimateDiff)です。他は変更しなくても動きます。
画像は僕が利用したときの設定です。各項目を翻訳すると、こんな感じの内容だと思います。
| Motion module | AnimateDiffで利用するモデル。 |
| Save format | 出力画像の形式。これはGIFだけONを推奨です。 仮にPNGがONになってると合成前の途中画像も出力されるのでかなりのゴミが残ります。 |
| Enable AnimateDiff | AnimateDiff機能の有効化。 |
| Number of frames | 全体のフレーム数。 |
| FPS | 1秒あたりのフレーム数。つまり、Number of frames / FPS が生成画像の全体秒数です。 |
| Display loop number | 表示時のループ設定。0で無限ループです。 |
| Closed loop | いわゆるフレームの最初と最後を繋げて、アニメーションを疑似無限ループにするための設定。 実際には繋がるようにAIが頑張ります。ただ、ほぼほぼ無理なのでNの無しを選択。もしくはDefaultのR-Pかな。 |
| Context batch size | モーションモジュールに1回で渡されるフレーム数。 ただし、現状はモデルが16フレームでトレーニングされてるので16推奨。 |
| Stride | モーションの最大ストライド(何これ?)。値は2の累乗で指定するがClosed loopがNだと1しか使えないよう。 |
| Overlap | コンテキスト内でオーバーラップするフレームの数。オーバラップなので何かを重ねるらしい。 |
| Frame Interpolation | Deforumを利用したフレーム補間。使うにはDeforum拡張機能が必要らしい。 |
| Interp X | 入力フレームを補間されたフレームに置き換える。分からんが触らなくてヨシ! |
ちなみに公式のドキュメントはここです。誰か代わりに翻訳してください。
https://github.com/continue-revolution/sd-webui-animatediff#webui-parameters
txt2imgでアニメーション画像を生成
成功率が物凄く低い印象。掲載可能な画像がこれくらいです。

ParametersSampler: DPM++ 2M Karras, Steps: 20, CFG scale: 7, Seed: 2460427250, Size: 512x512, Model: anything-v5-Prt-RE, VAE: vae-ft-mse-840000-ema-pruned.safetensors, AnimateDiff Model: mm_sd_v15_v2.safetensors
Prompt1girl, cute, long long hair, pink hair, blue eyes
NegativePromptEasyNegativeV2
img2imgでアニメーション画像を生成
こっちは比較的まともな画像ができる率が高いです。



ParametersSampler: DPM++ 2M Karras, Steps: 20, CFG scale: 7, Seed: 3169727010, Size: 512x768, Model: anything-v5-Prt-RE, VAE: vae-ft-mse-840000-ema-pruned.safetensors, AnimateDiff Model: mm_sd_v15_v2.safetensors
Prompt1girl, simple background, [(white background:1.5)::0.2], long hair, pink hair, blue eyes, looking at viewer, full body
NegativePrompt(EasyNegativeV2:1.0), extra fingers, fewer fingers


ParametersSampler: DPM++ 2M Karras, Steps: 20, CFG scale: 12, Seed: 1674806914, Size: 512x512, Model: anything-v5-Prt-RE, VAE: vae-ft-mse-840000-ema-pruned.safetensors, AnimateDiff Model: mm_sd_v15_v2.safetensors
Prompt1girl, cute, long long hair, pink hair, blue eyes, smile
NegativePromptEasyNegativeV2
あとがき
まだまだ発展途上でしょう。モデルの相性とか選ぶサンプラーによって簡単に絵が崩壊します。
後は画質?でしょうか。元の絵に対してかなり荒くなってる印象です。特に背景のジリジリが見てて辛い。
ちなみに通常の絵の生成と同様にステップ数を増やすことが出来ますが、生成に要する時間がありえないくらい増加するので無理です。
ほぼDefault設定の512x512をRTX3090で生成すると約30秒。適当にステップ数とか変更したら生成に1分以上の時間が必要でした。
その間はGPU使用率が100%でVRAMも過剰に使用されてる状態が続くので、グラボの寿命を考えたら辞めたほうがいいかと。
この記事は参考になりましたか?
コメント