
プログラムで利用するスタックとキュー、これをコンピュータサイエンスの視点から理解しましょう。
汎用的な知識を得ることで、効率のいいコードが書けたり、別のプログラミング言語を学ぶ時の役に立ちます。
スタック (stack)
データ構造の1つで、リストと同じく要素数が可変するコレクションです。
そしてスタックの特徴は要素の格納と取り出しにあります。
具体的には、要素を順番に格納するけど、取り出す時は最後に格納した要素から取り出します。
この仕組みをLIFO(Last-In First-Out)とか後入れ先出しと呼びます。
また、スタックではデータの格納と取り出しに名前があり、格納をpush(プッシュ)、取り出しをpop(ポップ)と言います。
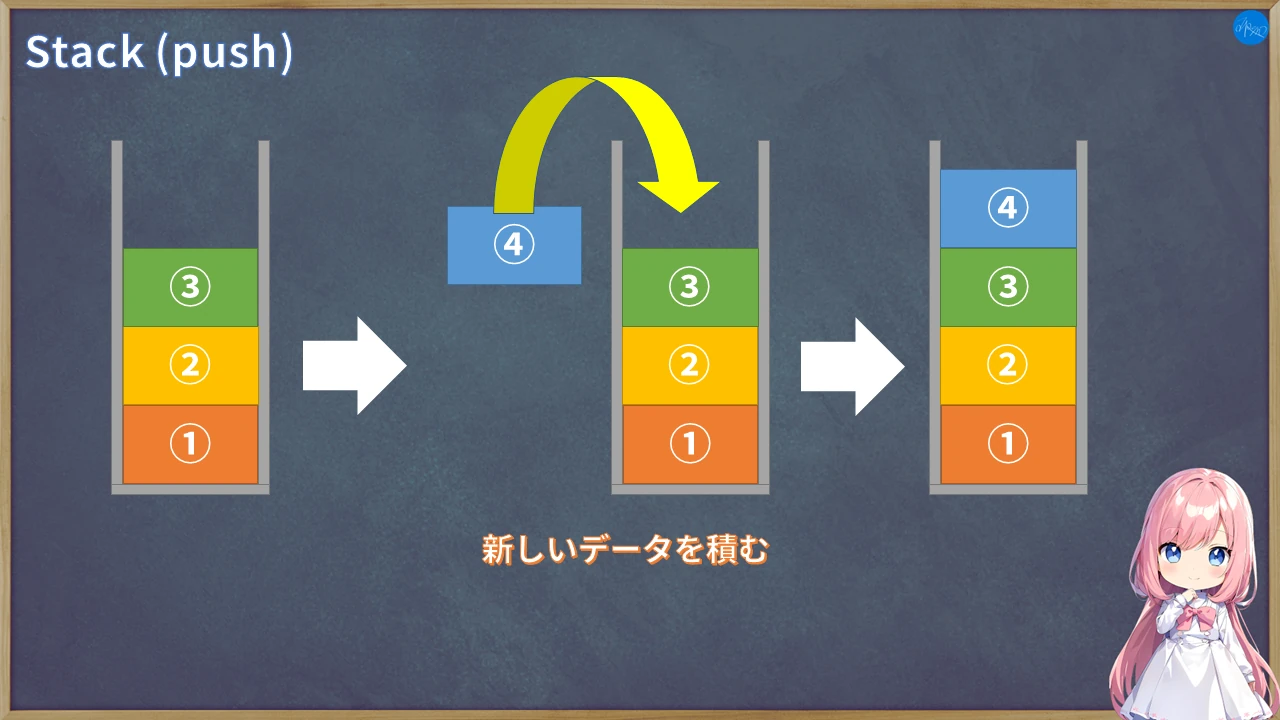


後から追加された要素が優先なんですね。

そうだよ。割り込みOKな世界だよ。
無法地帯じゃん。
キュー (queue)
こちらもデータ構造の1つで、スタックと同じく要素数が可変するコレクションです。
キューも要素の格納と取り出しに特徴があり、それ以外はスタックと一緒です。
こちらは、要素を順番に格納し、取り出す時は格納した順番に要素を取り出します。
この仕組みをFIFO(First-In First-Out)とか先入れ先出しと呼びます。
キューにもデータの格納と取り出しに名前があり、格納をenqueue(エンキュー)、取り出しをdequeue(デキュー)と言います。
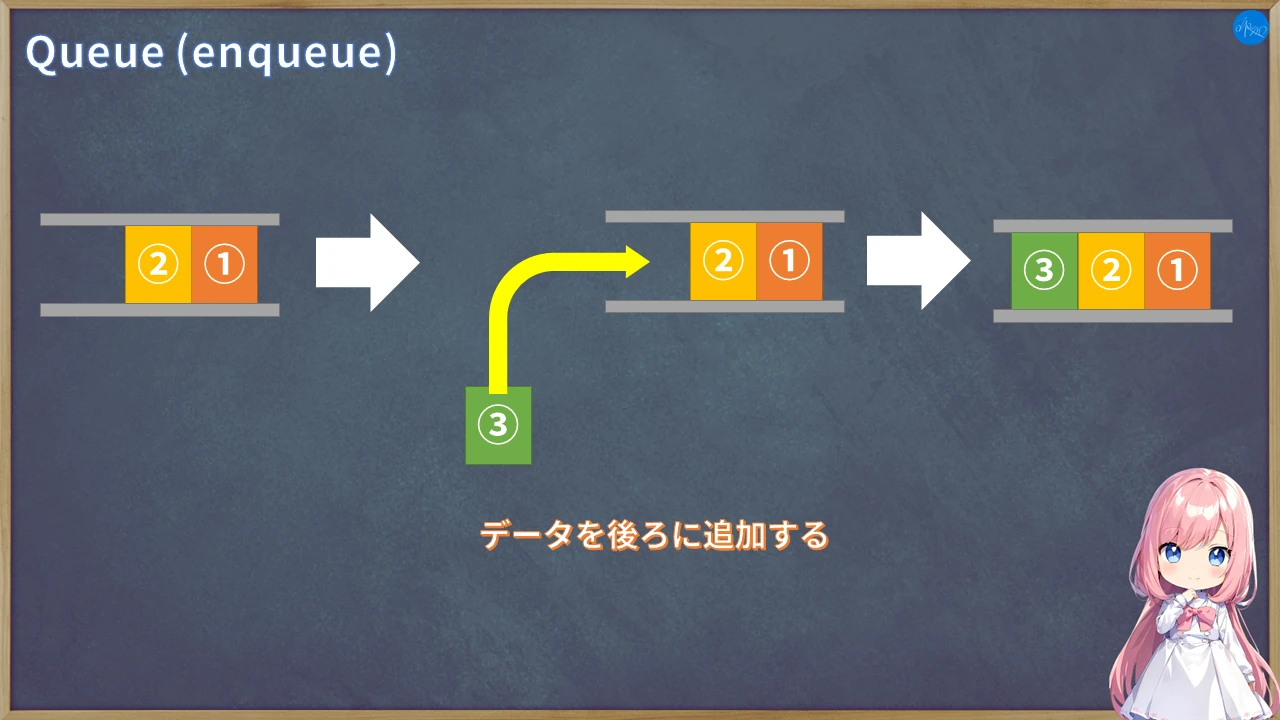

こっちはシンプルですね。
見た目から待ち行列って表現されることもあるよ。レジの会計とか、先に並んだ人が優先だよね。
インデックス (index) 経由のアクセス
仕組み上、インデックスの概念はありません。それは内部に格納されてる要素を知る必要が無いからです。
あくまで一時的に格納しておくか、取り出してデータを利用するか、と言う選択肢がメインです。
あとがき
このスタックとキュー、基本的にプログラミング言語に標準実装されてるので、自分で作る必要はありません。
今の時代にそんな言語はないと思いますが、仮に利用する言語に存在しない場合は頑張ってください。
◆ コンピュータサイエンスに関する学習コンテンツ
この記事は参考になりましたか?
コメント